Framework
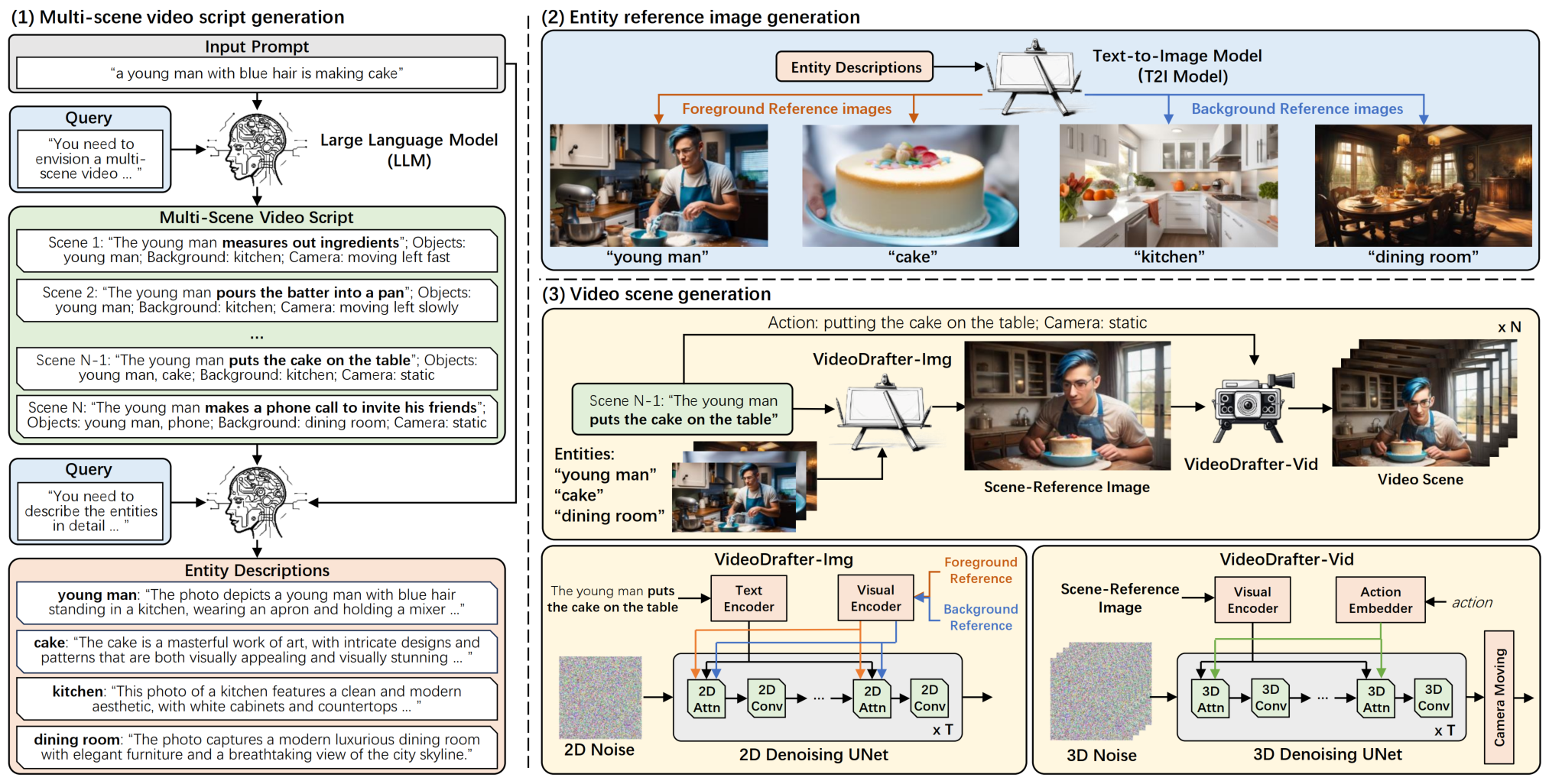
An overview of our VideoDrafter framework for content-consistent multi-scene video generation. VideoDrafter consists of three main stages: (1) multi-scene video script generation, (2) entity reference image generation, and (3) video scene generation. In the first stage, LLM is utilized to convert the input prompt into a comprehensive multi-scene script. The script for each scene includes the descriptive prompt of the event in the scene, a list of foreground objects or persons, the background, and camera movement. We then request LLM to detail the common foreground/background entities across scenes. These entity descriptions are fed into a text-to-image (T2I) model to produce reference images in the second stage. Finally, in the third stage, VideoDrafter-Img exploits the descriptive prompt of the event and the reference images of entities in each scene as the condition to generate a scene-reference image. VideoDrafter-Vid takes the scene-reference image plus temporal dynamics of the action depicted in the descriptive prompt of the event and camera movement in the script as the inputs and produces a video clip for each scene.


